Project Overview
This project began as an extension of Reinforcement Learning coursework at Georgia Tech, aiming to reimplement and expand upon DeepMind's groundbreaking paper "Human-level control through deep reinforcement learning" (Nature, 2015). The focus is on mastering the Atari Breakout game using Deep Q-Learning, with plans to incorporate innovations from the Rainbow DQN paper.
Technical Background
Deep Q-Learning
Deep Q-Learning (DQN) represents a significant advancement in reinforcement learning by combining Q-learning with deep neural networks. The algorithm learns a value function Q(s,a) that maps state-action pairs to expected cumulative rewards. The key innovation lies in its ability to handle high-dimensional state spaces through:
- Experience Replay: Storing and randomly sampling transitions to break temporal correlations and improve sample efficiency
- Target Networks: Using a separate network for generating target values to enhance training stability
- Frame Stacking: Processing multiple consecutive frames to capture temporal dynamics
Mathematical Framework
The DQN optimizes the Bellman equation:
Q(s,a) = E[r + γ maxa' Q(s',a')]
where γ is the discount factor, r is the immediate reward, and s' is the next state. The network is trained to minimize the temporal difference error:
L = (r + γ maxa' Q(s',a') - Q(s,a))²
Implementation Details
The current implementation includes:
- Uniform Experience Replay
- Prioritized Experience Replay
- Target Network Updates
- ε-greedy Exploration Strategy
Performance Analysis
Average Reward
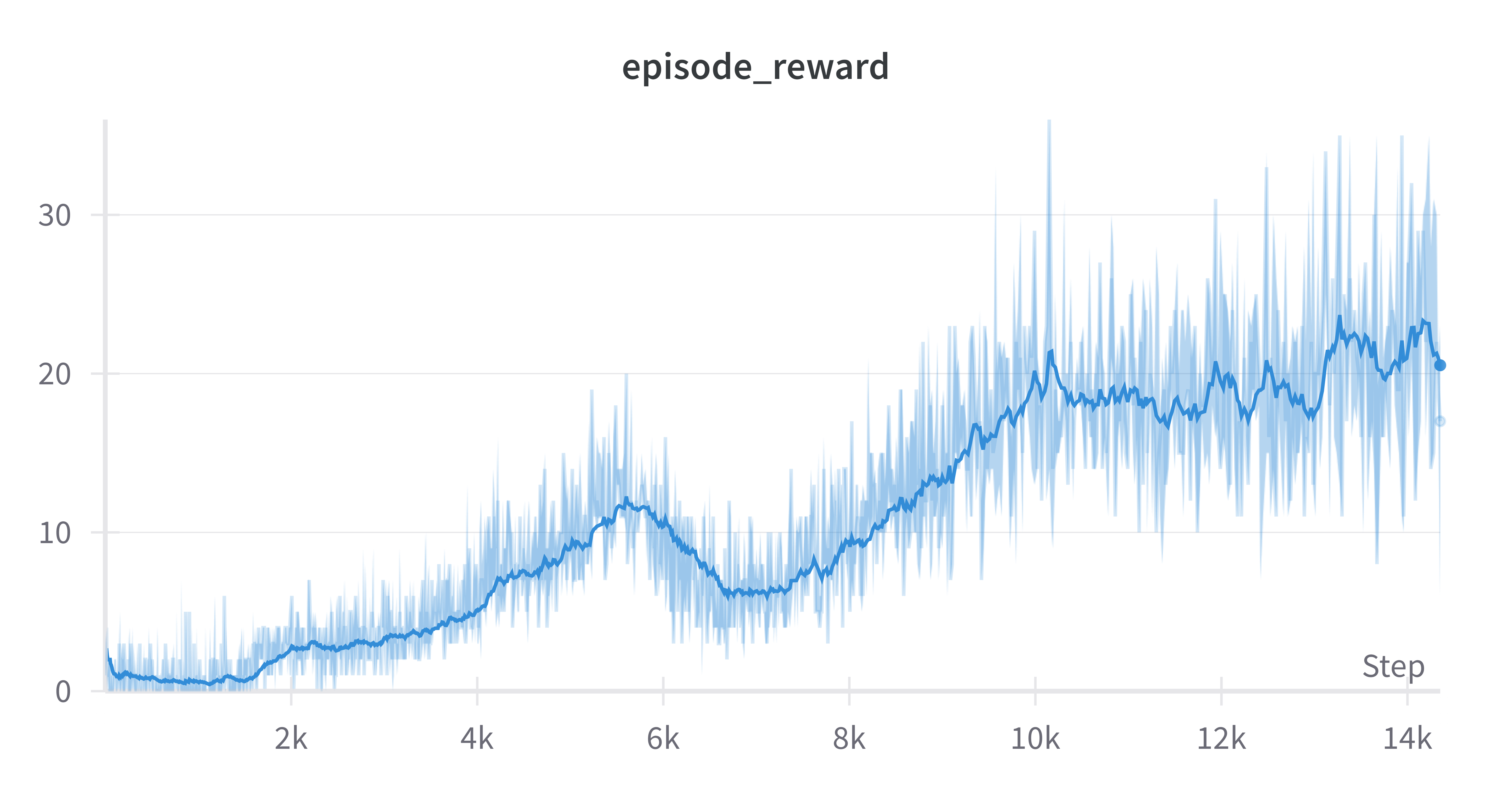
Loss Over Time

Future Work
Planned improvements include implementing additional components from the Rainbow DQN paper:
- Double DQN
- Dueling Networks
- Multi-step Learning
- Distributional RL
- Noisy Networks
These enhancements will be systematically implemented and evaluated to understand their individual and combined effects on performance.